The Null Device
Posts matching tags 'web'
2012/4/11
PHP: a fractal of bad design; a good essay on why PHP, one of the most popular web programming languages, is horribly, irreparably flawed:
PHP is not merely awkward to use, or ill-suited for what I want, or suboptimal, or against my religion. I can tell you all manner of good things about languages I avoid, and all manner of bad things about languages I enjoy. Go on, ask! It makes for interesting conversation. PHP is the lone exception. Virtually every feature in PHP is broken somehow. The language, the framework, the ecosystem, are all just bad. And I can’t even point out any single damning thing, because the damage is so systemic. Every time I try to compile a list of PHP gripes, I get stuck in this depth-first search discovering more and more appalling trivia. (Hence, fractal.)
Imagine you have uh, a toolbox. A set of tools. Looks okay, standard stuff in there.
You pull out a screwdriver, and you see it’s one of those weird tri-headed things. Okay, well, that’s not very useful to you, but you guess it comes in handy sometimes.
You pull out the hammer, but to your dismay, it has the claw part on both sides. Still serviceable though, I mean, you can hit nails with the middle of the head holding it sideways.
You pull out the pliers, but they don’t have those serrated surfaces; it’s flat and smooth. That’s less useful, but it still turns bolts well enough, so whatever.
And on you go. Everything in the box is kind of weird and quirky, but maybe not enough to make it completely worthless. And there’s no clear problem with the set as a whole; it still has all the tools.
Now imagine you meet millions of carpenters using this toolbox who tell you “well hey what’s the problem with these tools? They’re all I’ve ever used and they work fine!” And the carpenters show you the houses they’ve built, where every room is a pentagon and the roof is upside-down. And you knock on the front door and it just collapses inwards and they all yell at you for breaking their door.
That’s what’s wrong with PHP.I always thought of PHP as Perl's brain-damaged little brother.
2010/9/17
Dark Patterns is a list of deliberately deceptive or user-hostile website/interface design patterns, used by unscrupulous operators to deceive or exploit unwary users. These range from honest-but-hamfisted attempts to corral user behaviour into profitable channels (i.e., making it inconvenient to compare prices; sites which use JavaScript-based navigation to frustrate opening links in other windows do this) to various more underhanded tricks, ranging from sneaking unwanted items into shopping baskets, adding unsolicited recurring charges to spamming your friends under false pretexts to generally making it hard for the user to unsubscribe or do anything that reduces turnover. Featured offenders include the likes of Ryanair, various travel and consumer electronics retail sites, and Facebook (who get their own entry):
“The act of creating deliberately confusing jargon and user-interfaces which trick your users into sharing more info about themselves than they really want to.” (As defined by the EFF). The term “Zuckering” was suggested in an EFF article by Tim Jones on Facebook’s “Evil Interfaces”. It is, of course, named after Facebook CEO Mark Zuckerberg.
(via Boing Boing) ¶ 0
2010/6/18
The age of vector graphics on the web is drawing closer; Raphaël is a JavaScript library which gives you a portable way of drawing vector graphics, not only on all modern browsers but, amazingly enough, on Internet Explorer from version 6 upwards. (It uses SVG on modern browsers and VML on Microsoft's ones.) Anyway, Raphaël code looks like:
var paper = Raphael(10, 50, 320, 200);
var c = paper.circle(50, 50, 40);
c.attr({fill: "#000", stroke: "none"});
c.node.onclick = function() {
c.attr("fill", "red");
});
So how soon can you use this in your web sites? Well, it runs with most of the web browsers in use these days, though needs a 55Kb (20Kb gzipped) JavaScript file. You'll probably need to host this file yourself, neither Google nor Yahoo! seem to have added it to their public CDN systems yet (though perhaps it's only a matter of time).
2010/6/16
Some good news from London: Transport For London, who run the city's public transport networks, have announced that they will be opening access to all their data by the end of June. The data will include station locations, bus routes and timetable information, and will be free from restrictions for commercial or noncommercial use.
The data will be hosted at the London DataStore, a site set up to give the public access to data from public-sector organisations serving London. A few sets are already up, as well as a beta API which returns the locations of Tube trains heading for a specific station. Which could probably be worked into a mobile app to tell you when to start walking to the station. If they had something like this giving the positions and estimated arrival times of buses (whose travel times are considerably more chaotic than those of trains, and which often run less frequently, especially at night), that would be even more useful. (Some approximation of this facility exists in the LED displays, which are installed at some bus stops and sometimes are operational; a XML feed and a mobile web app would probably be a more cost-effective way of getting this information into the hands of commuters.)
Another thing that would be useful would be an API for the Transport for London Journey Planner; being able to ping a URL, passing an some postcodes or station names, a departure/arrival time and some other constraints, and get back, at your option, a maximum journey time or a list of suitable journeys, in XML or JSON format, would be useful in a lot of applications, from device- or application-specific front ends (i.e., a "take me home from here" mobile app) to ways of calculating the "inconvenience distance" between two points by counting travel time and changes (i.e.,in terms of travel convenience, Stratford is closer to Notting Hill than Stoke Newington, despite being further in geographical terms, as it's a straight trip on the Central Line).
2010/6/4
Some increasingly impressive things are being done with modern web browsers these days, taking advantage of new features in HTML5. A guy named Ben Joffe has developed a number of demos, including a full-featured 3D function plotter (using the canvas element) and a toroidal Tetris game. Another developer, going only by the name "Mr. doob", has developed some nifty 2D physics demos, including Ball Pool and Google Gravity. (Google, of course, entered the fray recently with their pure HTML5 implementation of Pac-Man.) Meanwhile, Apple, who are fighting their own (quite laudable, IMHO) battle against the dominance of Flash, have their own showcase of HTML5's capabilities, though it's coded to refuse to run on non-Safari browsers.
Chrome or Safari are recommended for the above demos; Firefox is still lagging behind in speed, though that's likely to improve in the near future. Firefox also has a new, experimental, API for manipulating audio data in JavaScript. (Apparently people are going to be doing FFTs in JavaScript in the future, which presumably won't make your browsing experience any faster.) It requires custom developer builds of Firefox (i.e., it's only for the hardcore at the moment), but people are already starting to experiment with it. Potentially most impressive so far is a project to port the Pd graphic audio programming language to JavaScript and have it run entirely in a browser. Meanwhile, here are some more audio API dems, including ones combining the audio APIs with WebGL to present 3D landscapes which respond to the beat in music and and graphic equalizer, sampler and speech synthesiser written entirely in JavaScript. I wonder how long until someone writes an entirely HTML5-based Ableton Live-style sequencer.
Typography is also shaping up nicely under HTML5, with a standard embeddable font format agreed upon. Google have released a web font embedding API, and made available several free font libraries through their content distribution system. They look, well, like free fonts; for those wanting more (and willing to pay for it), other groups of type foundries are jumping on the bandwagon; fonts.com has fonts from major foundries like Linotype, Monotype and ITC (at last, you can set your site in authentic Helvetica for people who aren't Mac owners), and über-cool Berlin-based outfit FontShop have joined the game as well (bringing the clean European stylings of the likes of FF DIN and FF Meta to the web). One notable omission, though, are 1990s grunge-typography hellraisers Emigre, who haven't yet made the leap.
Finally, here is an article on some of the things one can do with CSS3, from transformations (i.e., rotating entire elements, including text and layout) to keyframe animation, all done without a single line of JavaScript.
2010/2/25
The momentum towards proper typography on the web continues: now the FontFont type foundry, best known for clean, European typefaces like FF Meta and FF DIN as well as several Neville Brody geometrics, is selling web embeddable versions of its typefaces. The fonts are sold in DRM-free WOFF (the new open standard, currently in Firefox 3.6, but undoubtedly soon to make it into the WebKit browsers) and EOT (the Internet Explorer font format), which may be linked from style sheets. How much you pays depends on what license you get, and how many page views your site gets, and users are expected to configure their web servers to only give access to the fonts if the referrer matches the site (which won't stop anyone with a copy of curl or wget and half a clue from illicitly downloading them, but will stop other websites from casually sponging off your site's fonts). More details are here.
Which is a good start. Now if a few others like Emigre would join the @font-face party, then things would get more fun. (If Adobe made their fonts available for CSS embedding, non-Mac users might see this blog in Gill Sans, but that's probably not going to happen, as it's in Adobe's interest to keep HTML nobbled and divert those wanting more control to PDF or Flash.)
2010/1/13
What purports to be an interview with an anonymous Facebook employee, shedding some light on the inner workings of Facebook, technical improvements, privacy, and the more unusual dealings with its millions of users:
How do you think we know who your best friends are? But that’s public knowledge; we’ve explicitly stated that we record that. If you look in your type-ahead search, and you press “A,” or just one letter, a list of your best friends shows up. It’s no longer organized alphabetically, but by the person you interact with most, your “best friends,” or at least those whom we have concluded you are best friends with.
I’m not sure when exactly it was deprecated, but we did have a master password at one point where you could type in any user’s user ID, and then the password. I’m not going to give you the exact password, but with upper and lower case, symbols, numbers, all of the above, it spelled out ‘Chuck Norris,’ more or less. It was pretty fantastic.
I found a fake account created from Berkeley that used the profile picture and information from the brother of one of my very good friends. We looked up the guy who created the original profile, and he had never ever heard of him, never ever met him, obviously had never seen him. But this guy had evidently added him as a friend, and sadly he accepted it, but literally stole all of this guy’s information, created a fake account, and was communicating with himself from the fake account. He was writing on his wall and posting back to the “other person’s” wall. We found out the guy actually had about fifteen fake accounts that he created, stealing other users’ pictures and information to create the accounts, and was actually communicating back and forth with himself. Just to try to make himself appear cool, I guess?The unnamed Facebook employee also says that they're working on something named Hyper-PHP, which will compile PHP (which Facebook is written in) to machine code, which, they claim, will reduce CPU usage by 80%.
2009/11/3
Type foundries and browser makers have agreed on an open embeddable font format for the web. The Web Open Font Format, developed in collaboration by parties including the Mozilla project and geekier-than-thou type foundry LettError (which was cofounded by one Just van Rossum, whose brother created a somewhat popular programming language), is essentially a repackaged, compressed variant of TrueType/OpenType.
Somewhat surprisingly, it not only contains no DRM (which would have been a deal-breaker for open formats; Microsoft tried introducing an IE-only DRM-locked TrueType variant, but wasn't successful), but also contains all the data that a desktop font does, only slightly rejiggered to make it unusable in existing desktop systems. (I'll give them a week before someone writes a script that rips WOFF fonts to TrueType fonts.) This is surprising because the commercial font industry, producing something that's labour-intensive and skill-intensive but infinitely copiable, has until now jealously guarded its intellectual property, refusing to license its fonts for embedding in desktop formats. Instead, now they're keen to license them in slightly obfuscated versions, with the understanding that browsers enforce a same-origin linking policy unless there is additional license information. (I was thinking that, if the industry wasn't keen on letting its vector fonts out onto the web, it could have been possible to devise a resolution-limited font format, based on several sizes of bitmaps, with vector hints (i.e., "pixels 36-40 are a vertical stroke"), and generate all intermediate sizes using an interpolation algorithm. Such fonts would, of course, degrade if scaled above the maximum resolution in the file.) Another rationale could be that the market for web fonts could eclipse that for print fonts, and web font licensing would be easier to enforce (web sites, after all, are findable, and presumably unlicensed fonts would be easy enough to detect).
Licensing issues aside, WOFF promises to provide more than merely letting you put your favourite fonts on your web site. While Firefox 3.6 will have basic WOFF support, the next version of the specification promises to give more control, allowing web designers to fine-tune typographical parameters, selecting alternate forms including ligatures, different types of figures (lining and old-style, tabular and proportional), proper small caps, alternate figures (such as swash capitals) and such.
2009/10/19
Travel search engine of the day: Adioso. This is a new natural-language-based flight search system. It differs from sites like Kayak in that, rather than accepting simple queries in a set of fields (origin, destination, dates), it accepts queries as natural-language sentences, and allows a good deal of fuzziness. So, for example, if you want to go from London for a weekend in Barcelona in late November, you can ask for "London to Barcelona weekend late November", or if you just want to get out cheaply, you can ask for "London to anywhere under GBP100".
Well, you can if your destination is supported. The site appears to be Australian, and thus Australia and popular destinations from there (south-east Asia, the UK and US, and places along the "Kangaroo Route" to London) are well supported, while Europe (minus sunny holiday spots) is a bit patchy. The site found no flights from London to either Berlin or Stockholm, and drew a blank altogether at Reykjavík (the closest match it could find was Tel Aviv; I guess that sort of sounds like Reykjavík, if you're shouting across a noisy room or something). Flights across Australia it handles well, though, finding better prices than Kayak. In any case, the site claims to be in beta (though whether it's an old-fashioned beta or a Google-style permanent beta is uncertain), so with any luck, they'll improve it.
2009/10/15
2009/8/7
HTML5 Canvas and Audio Experiment. Twitter posts presented as a clickable particle swarm, with background music, and absolutely no Flash used. It's done entirely in HTML5, and, of course, needs a cutting-edge web browser to run on (Firefox 3.5 and Safari 4 both work, and so do Chrome and Opera, apparently).
The demo seems to be based on something named processing.js, which is, apparently, a port of Processing (i.e., a Java-like language for software artists) to JavaScript.
2009/7/14
Web interface of the day: A Chinese company has unified isometric pixel art and Google Maps-style draggable maps to make pixelicious city maps.

They have a map of Hong Kong in English, and maps of other Chinese cities (Chinese only; Google translation here). Not sure if it's much more useful than a 2D map, but it sure looks pretty.
Now perhaps someone can commission eBoy to do one of Berlin. Or of the internet.
2009/6/11
Two years after last.fm was bought out by CBS, who ran it as an autonomous unit, the three founders have handed in their resignations; they will stay on as consultants until September, after which control will be handed over entirely to CBS. After that, we can probably expect the servers to be boxed up and shipped to the US and the site to be rebranded as "MTV Online" or something, plastered with intrusive ads, and generally stripped of anything that made it cool in the first place.
So where do you go after last.fm? How do you display the superlative coolness of your musical taste to the world once last.fm is no longer fit to point people at? Well, there's libre.fm, which is still in alpha, doesn't look very good and has next to nobody using it. Libre.fm, though, is open-source, so you could easily run your own server. Perhaps the future will consist of people running their own scrobblers, or social networks providing scrobbling services to their users; your music stats will be available as standard XML feeds, with a XFN-style microformat link from your profile/homepage, letting the world know that this is what you've been listening to. Of course, one advantage a centralised site like last.fm had was that it could easily crunch the data and find recommendations or determine the compatibility of musical tastes, though if it's a web service, someone could write a third-party site to crunch exported music profiles. (Perhaps that someone will be Google or Facebook? Or perhaps Murdoch's struggling MySpace will leap at the opportunity, implement scrobbling, and then make a hash of it with obnoxious in-your-face Flash ads and a garishly unpleasant user experience.) As for finding upcoming gigs, event sites like upcoming.org, or Facebook's Event facility, could be expanded to be aware of band/artist names and search by user profiles.
2009/4/8
We haven't had a Wayne Kerr post for a while, so one is overdue. Anyway, I am Wayne Kerr, and if there's one thing I hate... it's websites attempting to coerce you into registering.
A while ago, there was an online newspaper named the International Herald Tribune. Owned by the New York Times but published in Paris, it was quite a good paper, with fairly incisive articles not too far from Economist territory. Then someone at head office decided to kill the brand and roll it into the New York Times brand, and iht.com became global.nytimes.com. And, with that, inherited the New York Times' draconian insistence on users requiring to register and log in to view their their precious content.
The New York Times, you see, is not satisfied with the standard online news business model (make their content freely viewable and linkable and sell ads to those surfing in on web links from wherever in the world they may be); that may be good enough for rabble like their London namesake, but the NYTimes' content is worth more than that. At the start, they even tried charging for online access to it. Of course, as Clay Shirky points out, this is not a viable business model for online news (current events cannot be copyrighted or monopolised, and someone can always do it cheaper), so the NYTimes soon dropped the demands for subscription. However, they have doggedly kept the other part of the equation: the insistence on users subscribing, remembering yet another username and password, and giving a valid, verified email address, as well as some juicy demographic information. Of course, there are ways around this; the most popular site on BugMeNot, a website for sharing free usernames/passwords to such sites, is the New York Times. However, such accounts usually have a very short lifespan; either they perish when the email verification period lapses or, failing that, the Times' web admins hunt them down and kill them, like an ongoing game of Whack-a-Mole.
The New York Times, however, is not the most irritating example of coercive registration; that accolade would probably go to a site named, ironically, Get Satisfaction. This is an external tech support site, used by a number of web 2.0-ish sites, including SoundCloud and ping.fm. As a web site, it is the very model of a modern website; rounded corners, quirky retro fonts (oh so San-Francisco-via-Stockholm), pastel-hued gradients, animated fades, you name it, it ticks the box; it would be perfect, but for one fatal flaw in the human interface design.
What somebody neglected to notice is the typical use case of such a site. One doesn't go to Get Satisfaction to socialise with friends, share photos or music, find a date or a flat, or do anything one does on a typical social web site; one goes there when one has gone to such a site and found that it doesn't work properly, and wants to notify somebody to fix this. Now when that happens, the last thing one wants it to have to think up another username and password, and be cheerfully invited to fill in one's profile and choose a user icon representing one's personality. As far as support forums go, less should be more, and Get Satisfaction, for all of its pretentions to being some kind of online clubhouse, falls short.
Not everything that isn't charged for is without cost; there is a cost, in time and finite mental resources, to keeping track of usernames and passwords. (Of course, you could use the same password across all sites, but that replaces a psychological/time cost with the security risk of all one's passwords being compromised.) And sites which put registration speed bumps in their users' way could find users going elsewhere where offers a smoother ride.
2009/1/28
Remember Muxtape, the web site where you could upload MP3s of songs you liked to make a virtual mix tape to send people, until the RIAA decided that it was too useful for them to not get paid for it and shut it down? Well, it's back, sort of. Or rather, there is a new site at muxtape.com. This time, you can't upload your stolen MP3s for anyone to criminally enjoy, but if you're in a band or make music, you can put your own music up for people to stream. Just like MySpace, only without the spammy Flash ads and generally atrocious user experience.
I was thinking that "Muxtape 2.0. Less sucky than the new Napster" would be a good slogan for it, but on reflection, this sounds needlessly sarcastic. How about: "Muxtape 2.0: less sucky than the new Napster or MySpace"?
2009/1/25
Some interesting notes from a talk about the scalability of social software delivered at the Web 2.0 Expo last September by Joshua Schachter of del.icio.us:
There are 3 Kinds of scale: technological, social, and personal. We’re going to briefly go through the technical stuff... Common access pattern is to have a screen, make a modification, requery the data, and then resend the results. We’re building a lot of these systems to be synchronous which is a huge performance hit. What you need is a queue not a database for processing messages asynchronously. Decouple interactive performance from the rest of the system. Huge win for Delicious. Now that we’ve got technical stuff out of the way…
Don’t go too far and expose too much information. A long time ago you could see how many friends you had and how many followers you had and compare who it was that was following but not a friend. The system allowed me to get angry at two people. People got freaked out by people ‘follow’ing them on delicious.
Wanted delicious to be a harmonious system. That’s why there were no conversations. Didn’t want people to come in and have religious wars. You have to be willing to deal with abuse, spam, porn, etc. His last year this got really bad.
Pretty urls are important. It’s prime advertising space. People will copy paste and link.
(via ![]() substitute) ¶ 0
substitute) ¶ 0
2009/1/7
LiveJournal sacks almost its entire US workforce, including all US-based engineers, leaving only a few financial and support staff. Panic ensues, with perverts worldwide stocking up on emergency supplies of Harry Potter slash fiction in case it disappears.
Chances are, the obligatory jokes about disturbing online subcultures aside, LiveJournal won't disappear overnight. For one, the cuts are in the US office, and LiveJournal is now Russian-owned, and is much bigger in Russia (in America, the typical LiveJournal user is a thirtysomething goth-scene veteran with an IT job, whereas in Russia, it's a mainstream media site). Given that most of the money and ad revenue come from the Russian operation, it presumably won't cost them much to keep running an English-localised rump site on the same servers.
In any case, I hope LiveJournal survives, because it has one thing none of the other sites have: no, not Harry Potter slash fiction; fine-grained social-network-based access control, i.e., the means to specify that posts are not just friends-only but only accessible to a subset of friends. Which might sound like a symptom of some kind of geek social neurosis, but is actually useful. (Consider, for example, a Facebook friends list, containing everyone from coworkers to family members to people you met at a party or festival; as on Facebook, you can't control who can read a posted item (it's all your friends or no-one), there are a lot of things you cannot or should not post; from boasting about faking illness to planning surprise parties for contacts, to discussing personal situations, so your Facebook stream becomes a stream of lowest-common-denominator banalities.) Something with Facebook-level usability and LiveJournal-level access control would actually be useful; maybe once the world emerges from the New Depression, someone will write something like that?
2008/12/10
The latest experimental technology to emerge from Google's labs is something called Native Client. This is an experimental means of running web content in native machine code in a web browser. It's X86-specific (so users of PowerPC Macs and the numerous ARM-based portable devices are out of luck here), though other than that, completely portable; the binaries are in a special format, and get a limited number of system calls standardised across Linux, OSX and Windows. There is even a version of Quake which will run in a browser, in any of these systems, should you have the plugin enabled.
Of course, by now, you're probably thinking "Are they crazy? That's the worst idea since nuclear-powered airliners". Google, though, claim that they have a robust security model. The instruction set available is restricted, with constraints placed on the format of the code, allowing a code inspection process to detect any dangerous instructions. Google argue their case in a research paper; I'm not sufficiently familiar with recent x86 assembly language to verify their claims, but it looks like they certainly put some thought into it. Of course, there are a lot of very bright people in places like Russia, Romania and China who would also put a lot of thought into it, to entirely different ends, so there are reasons to be concerned.
Why are Google doing this? Well, firstly, it must be said that this is an experimental project, and not a finished product. However, I doubt that this is to allow better animated web ads. For most user interface content (video, animation, &c.), Flash and such are sufficient. Where this is a big win is in CPU-intensive processing tasks, which are too expensive to do in JavaScript (even if compiled to native code through Google Chrome's V8 just-in-time compiler) or Flash. (At the moment, with fast machines, one can just about do audio synthesis/processing like Hobnox Audiotool in ActionScript; however, this is quite expensive in terms of resources.)
Where something like Native Client would really come in useful would be for coding web-based applications that do real heavy lifting without handing tasks off to a well-resourced server or relying on them being coded into Flash; for example, image editing or video editing as a web service. Google's paper presents a diagram of how such services would look; the front end would be written in JavaScript and/or Flash, whilst the native x86 code would sit in a separate, sandboxed Native Client process, performing the gruntwork on demand: rendering graphics, processing video, synthesising sound, animating the exploding heads of zombies or whatever is required. C/C++, in this case, is kept firmly under the stairs, with the UI code being left to higher-level languages.
Of course, such an idea opens all sorts of strategic possibilities for Google; if it works, it would reduce the desktop operating system to a commodity. If any kind of application can be used as a web service, why buy a copy of Windows (or a PC with the Microsoft Tax in the price)? In fact, why bother installing a full-scale Linux? They're already starting to make PCs with cut-down instant-on operating systems (typically Linux-based) in the ROM, so that if you can't wait for your Vista box to finish booting, you can boot into the instant OS and get a web browser. Now, imagine a box like this, only with the OS being able to run web apps at native speed, perhaps in an application-oriented browser like Chrome. Could this be the much talked about "Google OS"?
2008/11/19
Melbourne's community radio station 3RRR now has a new website. The new site appears to look somewhat more polished than the previous one, both visually and in terms of the design. (The URLs, for one, are clean, rather than being PHP scripts with CGI arguments tacked onto the end.)
The playlists linked from the program guide now go all the way back to the dawn of time (or 2004, in any case). (They had those playlists online in the old site, but the only way to get at them was to manually try different numbers in the aforementioned CGI arguments; here, they're indexed in nicely paginated indices going as far back as necessary.) Here is the first International Pop Underground playlist they posted online; it's interesting to note that Carew played My Favorite's Homeless Club Kids and various Stephin Merritt-related projects that week.
Also, RRR's website will have a subscribers-only section, which will apparently include expanded audio archives. Not sure what exactly this will entail, or indeed what Australian copyright law will allow.
2008/11/10
Are you trying to write something (a novel, perhaps, or a thesis) but are having trouble sitting down and getting the words out? Write Or Die could be useful. It's a web toy which uses operant conditioning to force you to keep churning out the words, or else...
Consequences:I wonder how long this is integrated with other forms of productivity tools, such as software development project trackers. Perhaps we'll soon see a "Code Or Die" plugin for Trac?
- Gentle Mode: A certain amount of time after you stop writing, a box will pop up, gently reminding you to continue writing.
- Normal Mode: If you persistently avoid writing, you will be played a most unpleasant sound. The sound will stop if and only if you continue to write.
- Kamikaze Mode: Keep Writing or Your Work Will Unwrite Itself
2008/9/3
WIRED has a piece by Steven Levy looking behind the scenes of Google's Chrome web browser project:
Because Chrome was supposed to be optimized to run Web applications, a crucial element would be the JavaScript engine, a "virtual machine" that runs Web application code. The ideal person to construct this was a Danish computer scientist named Lars Bak. In September 2006, after more than 20 years of nonstop labor designing virtual machines, Bak had been planning to take some time off to work on his farm outside Århus. Then Google called.
Bak set up a small team that originally worked from the farm, then moved to some offices at the local university. He understood that his mission was to provide a faster engine than in any previous browser. He called his team's part of the project "V8." "We decided we wanted to speed up JavaScript by a factor of 10, and we gave ourselves four months to do it," he says. A typical day for the Denmark team began between 7 and 8 am; they programmed constantly until 6 or 7 at night. The only break was for lunch, when they would wolf down food in five minutes and spend 20 minutes at the game console. "We are pretty damn good at Wii Tennis," Bak says.
Speed may be Chrome's most significant advance. When you improve things by an order of magnitude, you haven't made something better — you've made something new. "As soon as developers get the taste for this kind of speed, they'll start doing more amazing new Web applications and be more creative in doing them," Bak says. Google hopes to kick-start a new generation of Web-based applications that will truly make Microsoft's worst nightmare a reality: The browser will become the equivalent of an operating system.
Google also brought in reinforcements to implement the multiprocess architecture that allowed each open tab to run like a separate, self-contained program. In May 2007, it acquired GreenBorder Technologies, a software security firm whose technology was designed to isolate IE and Firefox activities into virtual sessions, or "sandboxes," where malware intrusions couldn't mess with other activities or data on your computer. When the deal was announced publicly, tech pundits wondered whether it meant that Google was going into the antivirus business. Only after the acquisition did GreenBorder's engineers learn that their job was to construct sandboxes for the tabs of a new browser. "It was confusing," says Carlos Pizano, one of the GreenBorder hires. "They would not say what they wanted to sandbox."Meanwhile, the Chrome beta's licensing agreement apparently gives Google rights to use anything you create using it for promoting its services. This alarming clause appears, however, to be the result of an oversight; the licensing terms appear to have been copied from Google's web applications, and make little sense for a BSD-licensed open-source web browser (after all, anyone who doesn't like the EULA could produce an EULA-free though otherwise identical version of the browser merely by recompiling it from the source).
2008/9/2
Google are apparently working on a new web browser. Named Chrome, the browser is designed more like an operating system which happens to be based on web technologies like DOM and JavaScript than a traditional browser; different pages are separate processes (and about time, too) and privileges are compartmentalised to fortify security. Meanwhile, the web rendering implementation is based on WebKit (the Apple/KDE open-source web engine), with a JIT-compiling JavaScript engine optimised for application from a Danish company named V8 (I wonder how it compares to Apple's Squirrelfish and Mozilla's new engine). Alas, there's no code available (and the URL given returns a 404); instead, Google have given us a beautifully drawn 38-page comic by Scott McCloud, illuminating the technical innovations and the reasons for them, in great detail and with no small amount of humour:
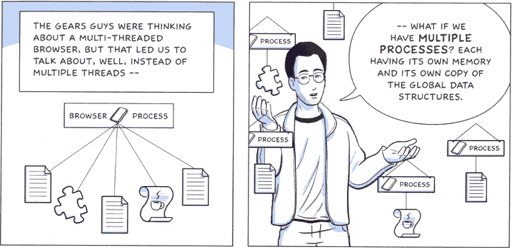
That's all the detail that seems to exist so far. There is a possibility that it's just an elaborate feint; Google could, in theory, have paid McCloud some huge sum to draw a comic to specification, peppered with technical versimilitude, purely in order to send Microsoft/Apple/Yahoo!/whoever's development teams on a wild goose chase. Though I suspect that there is an actual product there. For one, Google are known to use WebKit on Android.
 More importantly, though, a browser designed as a web application operating system (with the expectations of performance and stability that implies), rather than an information viewer with programmability grafted on as an afterthought (as is the case with current browsers), would line up rather nicely with Google's strategy to make the web into a first-class application platform.
More importantly, though, a browser designed as a web application operating system (with the expectations of performance and stability that implies), rather than an information viewer with programmability grafted on as an afterthought (as is the case with current browsers), would line up rather nicely with Google's strategy to make the web into a first-class application platform.
There are no details on what platforms Chrome will run; it is open-source (and other projects, or those willing to fork those, will probably have a field day with this), and the comic does mention Windows in one place, so presumably a Windows version is planned. I'm guessing that Google aren't doing this to help Microsoft sell Windows licences, though, so presumably this is not the only version planned. A Linux desktop version, running on top of X, is probably likely. Another possibility is it running over something lighter than the average Linux desktop, making a robust web-browsing appliance on which the browser meets the conventional definitions of an operating system; either Android or some other lightweight OS.
The other option, of course, is that this is an elaborate hoax, akin to the Photoshopped "spy photos" of new Apple Mac tablets and other fantastic gear that are a regular feature of gadget blogs. The fact that Google's Chrome page doesn't yet exist (at time of writing) does suggest this possibility. Though this would imply that the hoaxers had an enormous amount of time on their hands, excellent comic drawing skills and an uncanny mastery of the drawing style of Scott McCloud.
Update: Google have confirmed Chrome. It's initially a Windows product (presumably to win market share before IE8 comes along and shuts off Google's oxygen with its advertising cookie blocker), though Mac and Linux versions are in the works. The Windows version will apparently be out tomorrow.
2008/8/26
OpenTape is a open-source (PHP-based) implementation of the late lamented Muxtape, a web app which allowed people to make streamable online mix tapes. Now you too can get taken down by the RIAA.
2008/7/23
A few years ago, a few geeks in the UK, displeased with the Ordnance Survey's hoarding of taxpayer-funded mapping data, decided to do something about it, and so OpenStreetMap was born. Based on the same principle as Wikipedia, it used the power of internet-based grass-roots organisation to allow people to make their own maps, walking roads with GPS units, uploading the traces and giving them names. Out-of-copyright vintage maps and donated satellite data, among other things, helped a bit.
As you can imagine, in the early days, it wasn't much to look at. There were networks of roads, though most of them weren't named, and a lot were missing. You could sort of make out where you were, if you knew the place well. The interface was also somewhat slow and clunky, compared to Google Maps (a variation on whose draggable-tiled-map theme it was).
After a year or two, I looked at OpenStreetMap again today, and the story couldn't be more different. Where once was a slow, unusably incomplete tangle of rectilinear spaghetti, now there are street maps, as comprehensive and neatly rendered as Google and Yahoo!'s efforts, animated with a fast, responsive JavaScript interface (nothing you won't be familiar with if you haven't used Google Maps). Scrolling around the UK and zooming in on London brought familiar street plans, albeit in a new rendering. In fact, the (rather nifty) real-estate search mashup Nestoria even have a parallel version of their site which uses OpenStreetMap; the user experience is virtually identical to the main, Google Maps-based one. (For what it's worth, Nestoria uses something called Mapstraction, a browser-side JavaScript library that allows different mapping providers to be used interchangeably, but I digress.)
And as cool as a free-as-in-libre map of Great Britain might be (to one who lives there: pretty cool; your mileage may vary), that's not the extent of it. The OpenStreetMap project's scope is global; the developers created a canvas the size of the Earth's surface, with land masses and the locations of cities filled in, and allowed volunteers to contribute to it, wiki-fashion. Soon, OpenStreetMap had maps for Europe, North America and Australia like the commercial competitors. More interestingly, places which, to the big boys, are terra incognita often show up (in varying degrees) on OpenStreetMap.Some are impressively comprehensive; for example, OSM's maps of Reykjavík (and, indeed, Iceland's second city, Akureyri) and Buenos Aires are as thorough as anything you'd expect from Google, were they to bother. Harare, whilst looking quite sparse, is more detailed than on Google's maps, and the Papua New Guinean capital of Port Moresby seems fairly comprehensively drawn. Even Pyongyang has a surprising amount of detail (though one probably can't blame OpenStreetMap for most of the streets being seemingly unnamed); I imagine that as soon as North Korea allows unrestricted tourism, long before the first McDonalds goes up, tourists will be dragging cached OpenStreetMap tiles on their jailbroken iPhones as they negotiate its broad Stalinist boulevards.
Being based on free data, OpenStreetMap has other advantages over its commercial cousins. Each map comes with an Export tab, which lets you grab the displayed area in a variety of formats, from rendered pixmaps to SVG or PostScript to the actual raw data. With it being under the Creative Commons, you are free to do as you like with the data (subject to a "share alike" proviso if you commercialise it). And with it having the agility of the Wiki age, OpenStreetMap is starting to steal a march on its competitors; for example, it was the first map to show Heathrow Terminal 5 correctly.
Of course, OpenStreetMap is by no means perfect. parts of the world are still uncovered (much of the Russian interior), or only covered with major roads (much of Africa). And their rendering algorithm doesn't seem to do Chinese or Japanese characters, rendering most of China's place names as rows of boxes. (If one is picky, one could request transliterations of foreign character sets; perhaps this could be done as user-selectable layers.) There is no route-finding capability (of the sort that Google Maps has). But all in all, OpenStreetMap is very impressive, and a spectacular success.
2008/7/11
In an attempt to combat the more-megapixels-is-better delusion, the popular camera review site Digital Photography Review has added a new statistic to its camera specification databases: pixel density:
Pixel Density is a calculation of the number of pixels on a sensor, divided by the imaging area of that sensor. It can be used to understand how closely packed a sensor is and helps when comparing two cameras with different sensor sizes or numbers of photosites (pixels). Because the light collecting area and efficiency of each photosite will vary between technologies and manufacturers, Pixel Density should not be used as an absolute metric for camera quality but instead to get an impression for how tightly packed the imaging chip is.Tellingly, looking at the specs of the compact cameras I've owned, pixel density is one thing that's only getting worse. My current compact, a Canon PowerShot A570IS, clocks in at 29 MP/cm2, considerably behind its predecessor, a PowerShot A620 (19MP/cm2). Though it still does better than its immediate successor (with 32), and even Canon's high-end compact, the PowerShot G9, gets a marginally better 28. In contrast, my venerable old four-megapixel PowerShot G2 got 10 MP/cm2—which is almost in the DSLR ballpark—and it showed in the dynamic range and colour reproduction. Granted, it didn't fit into a pocket (unless one was wearing a large overcoat), but the photos did look good...
Hopefully the megapixel race-to-the-bottom will soon end as the public becomes aware of the fact that there is such a thing as pixel density and that it affects photo quality. Then maybe we'll see a new crop of 6-megapixel compacts, and a public that's aware that they actually take better pictures than higher-density ones.
(via ![]() reddragdiva) ¶ 0
reddragdiva) ¶ 0
2008/6/17
The New York Times has a piece on the works of Paul Otlet, a Belgian who, between the late 19th century and World War 2, invented early forms of hypertext, search engines, the semantic web and even social software. Of course, not having digital computers to work with, his "Mundaneum" had a vaguely Terry-Gilliam's-Brazil quality about it, relying on telegraphs, vast numbers of index cards, armies of clerks and analogue terminals referred to as "electric telescopes".
The government granted them space in a government building, where Otlet expanded the operation. He hired more staff, and established a fee-based research service that allowed anyone in the world to submit a query via mail or telegraph — a kind of analog search engine. Inquiries poured in from all over the world, more than 1,500 a year, on topics as diverse as boomerangs and Bulgarian finance.
Since there was no such thing as electronic data storage in the 1920s, Otlet had to invent it. He started writing at length about the possibility of electronic media storage, culminating in a 1934 book, “Monde,” where he laid out his vision of a “mechanical, collective brain” that would house all the world’s information, made readily accessible over a global telecommunications network.Alas, when the Nazis took Belgium, they destroyed most of what he had achieved and he died a broken man, all but forgotten until a graduate student found what remained of the Mundaneum in 1968. 10 years ago, a museum dedicated to Mr. Otlet's singular vision was established:
The archive’s sheer sprawl reveals both the possibilities and the limits of Otlet’s original vision. Otlet envisioned a team of professional catalogers analyzing every piece of incoming information, a philosophy that runs counter to the bottom-up ethos of the Web.
Just as Otlet’s vision required a group of trained catalogers to classify the world’s knowledge, so the Semantic Web hinges on an elite class of programmers to formulate descriptions for a potentially vast range of information. For those who advocate such labor-intensive data schemes, the fate of the Mundaneum may offer a cautionary tale.
2008/5/4
Microsoft has abandoned its attempt to buy Yahoo!, having failed to reach an acceptable price and decided against a hostile takeover (which would have involved the legal equivalent of house-to-house combat and probably ended up with most of Yahoo's best people leaving for Google or someone). Across the world, millions of Flickr and del.icio.us users (particularly those who don't use Windows) breathe a little more easily.
Of course, it's not necessarily over; Yahoo's share price will almost certainly slump in the short term, and if their attempts to turn their business around don't bear fruit, Microsoft could come back a few months later and pick them up for less. Unless, of course, they buy AOL instead.
2008/3/26
Muxtape.com is a new web application which allows users to make online mix tapes by uploading MP3s, which then can be arranged into a "mix tape" people can listen to online. It gets bonus points for the interface, which has a minimal elegance about it and does everything other than the actual music playing in DHTML. On the down side, you only get to put 12 MP3s in your mix, and are not supposed to have more than one mix.
(For what it's worth, my one's here.)
2008/1/18
Yahoo has announced that it will be an OpenID provider, allowing users to log into OpenID-enabled sites using their Yahoo ID. Of course, as Yahoo want everyone to have a Yahoo ID (which gives them clout in targeted advertising), they have no plans "at this time" to accept OpenID logins from other providers.
2008/1/9
Something I didn't know until today: the Facebook API includes a complete SQL-style query language for querying one's social graph, which allows you to do things like:
SELECT name, pic, status, music FROM user WHERE uid in (select uid2 from friend where uid1 = 1234567890)FQL, as it's called, can be called from the Facebook API, or you can play with it here (using the fql.query method).
2007/12/29
2007/11/26
As social network websites with user-generated content become mainstream, online dating websites, as a category, are dying. Which makes sense: the only reason that online dating sites (which are like the online equivalent of leks, full of of people putting on their best dating-profile face and saying whatever they think makes them look more attractive), now look even more starkly naff than they did when they were the only game in town. Or, when there are alternatives, going anywhere specifically to pick up doesn't reflect well on oneself:
There's a reason Mulligan and Helm are above online dating. They're part of the social networking generation. Neither would admit to going on sites like Facebook or News Corp.'s MySpace (NWS) expressly looking to hook up. And that's precisely why it's such a better answer to the problem of meeting someone interesting. It's like going to a bar with your friends. Maybe you are going to meet someone special, but maybe you're just going to hang out with your friends too. You can play it cool. "MySpace and Facebook feel like going to a nature preserve, [whereas] a dating site is like walking past a bunch of animals in cages at the zoo," Helm says.
Other sites that meld user-generated content with social networking to accomplish certain tasks can be even handier. Consider Yelp, where people write reviews of their favorite restaurants, bars, and other haunts, or Digg, where users vote and post comments on their favorite online stories. You can scope out Yelp or Digg users on their profile pages, which show pictures and list basic likes and dislikes. But you can really find out about them from the locations they Yelp about or stories they Digg. Both sites have features that even let you connect with fellow users based on shared traits. It's like a version of eHarmony you don't have to opt into. And while many online dating sites charge a fee, most new Web sites are free.And use of social web sites isn't the only thing that has gone mainstream; the Business Week article linked above signs off with:
The Web moves fast. And sorry online dating, but you just didn't keep up. In the parlance of the kids who won't use you, you got "pwned."
2007/9/24
Why is it, you may have asked yourself, that a technological civilisation that can put men on the moon, map the human genome and create the Nintendo Wii and the iPod can't make a standards-compliant web browser that doesn't leak memory like a sieve. Well, there's some good news on the horizon: the developers of Firefox have embarked on a memory leak eradication drive:
Aaron suggested having an "about:memory" page showing a breakdown of Firefox's memory use (bug 392351). When I pointed out the bug to Brendan Eich, he excitedly assigned the bug to himself.
Robert Sayre created a script to load random pages and see whether they cause leaks. The random URLs come from the Yahoo directory (biased toward older, top-level pages), del.icio.us (biased toward newer, geeky pages), and AltaVista (biased toward pornography).I see they have their use cases covered.
Steve England tested the top 500 web sites, finding two leaks. Later, he tested the top 20 Firefox extensions and found leaks in several of them.And there are some interesting user comments on the page.
Could I suggest a test of a 10 minute session of scrolling and zooming around in google maps hybrid mode as something guaranteed to to eat over 1GB of memory?I'd venture to say, from personal experience, that Yahoo! Maps (which appears to be a clone of Google Maps, and and is, to the best of my knowledge, only used for geotagging photos in Flickr) appears to chew up more memory than Google Maps. Which is rather funny, what with Yahoo! employing some of the brightest minds in AJAX development today (Douglas Crockford, for one).
Anyway, good luck to the Mozilla developers. Speaking as one in the habit of leaving lots of windows open in a session, I hope that this will lead to a browser that doesn't chew up all of the computer's resources if used for more than a few hours.
2007/9/9
In 2005, Olia Lialina wrote A Vernacular Web, a survey of the culture of amateur web design some years ago, cataloguing ubiquitous pheonomena like starry backgrounds, "Under Construction" signs, rainbow horizontal rules and animated "Mail Me" graphics. Now, she has returned to the subject with a look at how things have changed over the past few years in the world of non-professional web pages:
Home pages no longer exist. Instead, there are other genres: accounts, profiles, journals, personal spaces, channels, blogs and homes. I’d like to pay special attention to the latter ones.
If you look at the most viewed layouts on MySpace, you’ll notice that most of them have a big picture as a background, which repeats itself horizontally and vertically. This back-to-1996 design flaw is now forever linked to Web and amateur users, and nobody cares about eliminating it – neither services nor users themselves.
Firstly, glitter became a trademark of today’s amateur aesthetics, and I’m certain that in the future sparkly graphics will become a symbol of our times, like “Under Construction” signs for the 90’s. Glitter is everywhere (in the universe of user-generated pages), it has become a meta category. It has absorbed all other categories of ready-made graphics – people, animals, buttons, sex graphics.
Starry backgrounds represented the future, a touching relationship with the medium of tomorrow. Glitter decorates the web of today, routine and taken-for-granted.Lialina also mentions the ubiquity of cat-themed graphics on the web of today (LOLCats and "Kitten Of The Day"), though declines to go into it, or theorise about the idiosyncratic phraseology and typography used in LOL* graphics.
2007/8/20
Brad Fitzpatrick, the founder of LiveJournal and architect of OpenID, has put forward his thoughts on the social graph problem — which is to say, the present state of affairs in which each social software application has its own social graph (of which user is connected to whom) which its users have to independently maintain — and how to go about aggregating these graphs into something less unwieldy:
Currently if you're a new site that needs the social graph (e.g. dopplr.com) to provide one fun & useful feature (e.g. where are your friends traveling and when?), then you face a much bigger problem then just implementing your main feature. You also have to have usernames, passwords (or hopefully you use OpenID instead), a way to invite friends, add/remove friends, and the list goes on. So generally you have to ask for email addresses too, requiring you to send out address verification emails, etc. Then lost username/password emails. etc, etc. If I had to declare the problem statement succinctly, it'd be: People are getting sick of registering and re-declaring their friends on every site., but also: Developing "Social Applications" is too much work.
Facebook's answer seems to be that the world should just all be Facebook apps. While Facebook is an amazing platform and has some amazing technology, there's a lot of hesitation in the developer / "Web 2.0" community about being slaves to Facebook, dependent on their continued goodwill, availability, future owners, not changing the rules, etc. That hesitation I think is well-founded. A centralized "owner" of the social graph is bad for the Internet.Brad has written down a set of goals for a project to open up the social graph, in a way that allows sites to interoperate gracefully. This will include a common infrastructure that manages the social graph data, within an architecture which (much like OpenID) allows anyone to operate their own servers, and prevents any one entity from owning the graph. This will have an API, which returns all equivalent nodes of a node (i.e., given an identity on one service, the owner's identities on all other services registeded), the edges in and out of a node, the aggregated friends of a node across all services, and any missing friends (i.e., any pairs of nodes connected on one service but not another).
From the user's point of view, this will allow some fairly nifty magic to happen, saving users the hassle of registering on yet another social network site and rounding up their friends:
A user should then be able to log into a social application (e.g. dopplr.com) for the first time, ideally but not necessarily with OpenID, and be presented with a dialog like: "Hey, we see from public information elsewhere that you already have 28 friends already using dopplr, shown below with rationale about why we're recommending them (what usernames they are on other sites). Which do you want to be friends with here? Or click 'select-all'."Brad acknowledges that there will be uncooperative sites, who, owning the lion's share of the social-networking sphere, don't see it in their interest to prioritise interoperating with other sites (no names are named, though I'm betting that it'll be a cold day in Hell before MySpace plays nice with something like this; after all, it may tip their users off to the existence of other sites and depress banner-ad impressions). Thus he proposes a browser add-on which implements the system on uncooperative sites, by means of screen-scraping.
What's happening with this proposal? so far, they have prototypes of the APIs, working on the data for 5 sites (LiveJournal and Vox are, not surprisingly, two of them), the start of a Firefox plug-in to drag MySpace, kicking and screaming, to the party, and the start of a website allowing users to register their points of presence in social networks; a limited beta is expected at some time in the future. There are apparently a lot of people from different organisations working on this, much as there were on the OpenID project, and a Google group has been set up for discussion of the details.
Note that this only covers social network (i.e., "x is a friend of y") data, and not the actual content (birthdays, photos, favourite movies/bands). There is another project named Move My Data, which aims to make the actual user data portable between accounts, though so far it seems to consist of a vague proposal.
2007/5/30
Oh-oh; music-based social networking site last.fm has just been bought by old-media dinosaur CBS, for £140m. CBS say that last.fm will retain its own identity (as opposed to being rebranded as "MTV 2.0" or something) and its managing team will remain in place, so hopefully it won't turn to dross immediately.
2007/4/17
In the landscape of the user-generated web, MySpace stands alone. Not because of any technical superiority or leadership; in fact, the site itself gives off a strong whiff of inelegance and half-bakedness. It stands alone, quite literally, by refusing to play nice with rival websites. MySpace is a jealous god, whose first commandment is "thou shalt have no other sites before me". Hence its "blog" functionality has no RSS feeds or permalinks, it doesn't ping or query other sites, and don't even think about APIs or mashups. MySpace may be mentioned in the same breath as "Web 2.0" (much in the way that, say, Lily Allen is "underground hip-hop"), but it is strictly Web 1.0; very Old Testament.
Up until now, MySpace's lack of interaction has been a passive one; users could embed third-party content from other sites in their pages. But now, MySpace has started blocking links to rival sites like photo-sharing site PhotoBucket.
What doesn't make sense is Fox's assumption that the MySpace stronghold (81 percent of the social networking market) can withstand a backlash from developers and users who prefer a more open environment -- even one that hosts ads and the Flash-based widgets that MySpace says are a security threat. In the end, MySpace is just one mass migration away from becoming Tripod.
The company's efforts to circle the wagons and push offending third-party widgets from its site comes at an interesting time. Its closest competitor, Facebook, has unannounced (but confirmed) plans to open its site to third-party widgets for the first time. Ultimately, the two sites could come to resemble each other, but which will users prefer?MySpace users are a stoical lot, willing to put up with having their spaces plastered with flashing, buzzing ads and to make do with late-20th-century levels of functionality in the age of the dynamic mashup; however, some are speculating that as Murdoch tightens his grip and attempts to get value from the $580 million he spent on the site, users will realise that MySpace is not their space but the online equivalent of a tightly controlled shopping mall and move on to more open sites.
2007/3/18
In their infinite wisdom, the management at Yahoo! head office decided, some time after buying Flickr, to eliminate old-sk00l Flickr accounts, and force everyone to get a Yahoo! ID. With the date of the shutdown looming (in two days' time), I have reluctantly walked the plank, Yahoo!'s cutlasses at my back, and jumped into the shark-infested waters of getting a Yahoo! ID (I had at least one, from years ago, which I didn't use, though I have now created a new one), and tying my Flickr account to it. My new ID is the same as my last.fm username, for what it's worth.
The ID came with free webmail, as everything does these days. Yahoo!'s new webmail client is quite an impressive showcase for the power of their AJAX user interface library, and does some quite slick things. Unfortunately, Yahoo! being considerably more corporate than Google, the pane in which you see your emails is tiny, with the bulk of the space being given over to a large, animated banner ad. (This is in addition to context-sensitive text ads.) I think I'll stick with Gmail for the time being, thanks.
I just hope that Yahoo! don't decide to fold Flickr into their mainstream photo-sharing site or otherwise attempt to maximise their revenue by cluttering it with ads.
BTW, those using Uploadr.py on Linux (or similar systems) to post to Flickr may be interested in knowing that there's now a new version that plays nicely with Yahoo! authentication.
2007/2/28
JavaScript 1.7, the version used in Firefox 2.0, has a raft of Python-inspired features, including generators and list comprehensions. So now, you can do things like:
function fib() {
var i = 0, j = 1;
while (true) {
yield i;
[i, j] = [j, i + j];
}
}
and
var evens = [i for (i in range(0, 21)) if (i % 2 == 0)];And, indeed, bulk assignments, like:
[a, b] = [b, a];That is, as long as you're not concerned about your code working on non-Mozilla web browsers. (I wonder whether Microsoft, who still have well over 80% of the browser market, will adopt these new features.)
2007/2/8
Google Maps has finally launched a full Australian edition. The site, located here, doesn't provide any more actual map data than Google has had for a year or two, but does now have an index of businesses, so searches like "cafes in 3068" or "computers in melbourne" will yield useful results.
2006/12/4
UnSuggester is a book recommendation engine in reverse; enter a book you liked, and it'll give you a list of books you probably won't like. Apparently, fans of William Gibson's Neuromancer and Michael Moore's Stupid White Men would least want to read books on theology, the opposites of Marx & Engels' Communist Manifesto look like erotica novels, Bulgakov's The Master and Margarita is the least like an array of romance novels, Star Wars novelisations and theological texts, and the opposites of Design Patterns are mostly chick-lit, whereas The Little Prince finds itself to be the antithesis of thrillers and scifi novels. Meanwhile, people who read Illuminatus! are unlikely to read Freakonomics, and the opposite of The Da Vinci Code, with its simplistic structure and grand revelations, appears to be, naturally enough, French postmodernist philosophy.
2006/11/6
The UK's Ordnance Survey, the government agency which uses taxpayers' funds to create incredibly detailed maps and then licenses them under prohibitive licensing terms and steep fees, seems to be thawing to open access to its data, and is experimenting with a Google Maps-style JavaScript interface, to be named "OpenSpace". Note that if it is released, it will only be for noncommercial use, and the actual data itself won't be made public. I wonder how much this is a result of pressure from OpenStreetMap and other guerilla mappers encroaching on its monopoly.
2006/10/9
It's confirmed: Google has bought YouTube, for US$1.65bn, snatching it from the grip of old-media behemoths like Viacom and News Corp. Which means that it stands a decent chance of maintaining its existing principles, rather than turning into some kind of ad-spammy, contributor-hostile conduit for corporate marketing.
2006/2/27
Pub database + Google Maps = PintSearch. It only seems to cover London now, and, as you might expect, in many places you can't click to drag the map without selecting a pub.
2006/2/15
The Nintendo DS, sometimes dismissed as the Sony PSP's poor cousin, is starting to look like an interesting platform. For one, whilst Sony's unit is largely dominated by fairly conservative mainstream fare like driving/sports/gang-warfare/first-person-shooter games, the dinky DS, which lacks the raw power to compete in the graphics-machismo stakes but has two screens, one of them touch-sensitive, and a microphone, has been capitalising on this with more conceptual and experimental titles. One which has been raved about recently is Electroplankton, an artificial-life-based algorithmic-music-composition game/toy/tool developed by Japanese multimedia artist Toshio Iwai. Electroplankton was apparently the most popular Japanese import to the US, though now has been released there, and at least one musician has made an album using it, and is using it in live performances.
On a more practical note, the Opera web browser is about to be released for the DS; Opera will be a cartridge which allows users to browse the web via Wi-Fi from their DS. I wonder how long until Skype or someone release a VOIP cartridge, turning the DS into an internet telephony handset.
Meanwhile, some hobbyist hackers have written a personal organiser package for the DS. It's a download, and needs some hacking to get it to work. And someone else is manufacturing and selling cartridges for running homebrew software on a DS. The PassMe cartridges plug into the cartridge port and take a legitimate game cartridge, which they use for authenticating the code downloaded onto them as legitimate; they are used for running homebrew titles, and absolutely not, it must be stressed, p1r4t3d games. It's not quite clear how one downloads the software image onto the cartridge, though; I imagine it may use proprietary software, possibly running only on Windows.
(via Make, Boing Boing) ¶ 0
2006/1/21
This site lets you play old Commodore 64 games in your browser, without downloading any software. (Assuming your browser has Java and is on a reasonably fast machine, of course.) The experience includes everything, from SID chip sound to cracker-group intro screens, though your frame rate may vary (it feels roughly like C64 emulation on a 486-class machine in the mid-90s). A new game is added every day; today's addition is Giana Sisters, a Mario Brothers knockoff with added 1980s hairspray.
2005/12/9
A group of browser vendors has published a preview of HTML 5.0, also known as Web Applications 1.0. Users of browsers in the future can expect a lot of nifty enhancements, including new web form controls (drag and drop, flexible grids, progress meters), more DOM events to facilitate AJAX programming, more intelligent web forms (including support for minimum/maximum values and automatic validation) and a canvas element which can be drawn on using JavaScript (and for which the demos include a pure-JavaScript SVG viewer and a Wolfenstein-style 3D maze game). The HTML 5 features should make AJAX applications more efficient and powerful.
Web Applications 1.0 is a proposal by a group named WHATWG (the Web Hypertext Application Technology Working Group), which consists of people from various browser developers, from projects such as Opera, Mozilla and Safari. It appears that the elephant in the centre of the room is the conspicuous absence of Microsoft, who own most of the browser market share. Which is hardly surprising, as if AJAX becomes a reality, it could cannibalise Microsoft's OS lock. Perhaps we can expect MS to specify their own, incompatible AJAX-esque technologies that are locked to their browser and technologies?
2005/11/6
This month is the 15th anniversary of the creation of the first web page, and ultimately the World-Wide Web; an occurrence made more remarkable when you think that something like that could not arise today, because the brief window of the possibility of disruptive technologies has largely been closed by powerful vested interests aware of their consequences:
Imagine a network with the opposite design. Imagine that your terminal came hardwired from the manufacturer with a particular set of programs and functions. No experimenting with new technologies developed by third parties instant messaging, Google Earth, flash animations...Imagine also that the network was closed and flowed from a central source. More like pay-television than web. No one can decide on a whim to create a new site. The New York Times might secure a foothold on such a network. Your blog, or Wikipedia, or Jib Jab need not apply. Imagine that the software and protocols were proprietary. You could not design a new service to run on this system, because you do not know what the system is and, anyway, it might be illegal. Imagine something with all the excitement and creativity of a train timetable.
The web developed because we went in the opposite direction towards openness and lack of centralised control. Unless you believe that some invisible hand of technological inevitability is pushing us towards openness I am a sceptic we have a remarkable historical conjunction of technologies.
Why might we not create the web today? The web became hugely popular too quickly to control. The lawyers and policymakers and copyright holders were not there at the time of its conception. What would they have said, had they been? What would a web designed by the World Intellectual Property Organisation or the Disney Corporation have looked like? It would have looked more like pay-television, or Minitel, the French computer network. Beforehand, the logic of control always makes sense. Allow anyone to connect to the network? Anyone to decide what content to put up? That is a recipe for piracy and pornography.Then again, the WIPO-sanctioned, corporate-controlled walled-garden web would have probably met with an underwhelming reception and withered away like AOL or the original MSN, while, somewhere, an underground, decentralised network evolved by a series of accidents. Unless, of course, they banned and eradicated the original, anarchic Internet and replaced it with Internet 2.0™, a network designed from the ground up for control, and somehow managed not to send the communications-dependent world economy into a depression in doing so.
2005/8/30
Today is the 10th anniversary of the Opera web browser, which is said to be the best browser. As such, they're having a virtual party; other than competitions, games and MP3s of music by Opera developers, they're giving away free registration codes, for one day only. I.e., if you go to the page now and enter an email address, you can register a copy of Opera for free and never be bothered by ads, all without spending US$39 for the privilege.
(via ![]() substitute) ¶ 0
substitute) ¶ 0
2005/7/20
News Corp. buys MySpace, which was the next Friendster/Orkut and/or where all the angsty emo teenagers moved to after LiveJournal became too full of grown-ups. Murdoch paid US$580m for it. No word on whether MySpace.com is going to start showing prominent flags, "We Support Our President" banners and/or ads for Ann Coulter books (or, in Britain, a "Chav And Proud" logo in Burberry check).
(More seriously, News Corporation is known for its fine-grained news-management deployed strategically to influence elections. Perhaps their acquisition of a social-network site, and building up an internet division, could be used to enhance this on an even finer level. Imagine, for example, if they have a system capable of predicting a user's political sympathies, based on their social contacts, web links, and/or keyword analysis of their comments/journal entries. Those with political opinions in line with News Corp. strategic goals could be served with ads and/or news content designed to stir them into activism, whereas those with opposing inclinations could be fed toned-down versions of news articles and ads for escapist entertainment designed to depoliticise them. The possibilities are endless.)
2005/6/30
It looks like Microsoft are embracing the DHTML/Javascript trend; at least when it comes to reducing the quality of the non-IE browsing experience on their sites. And they've also announced an AJAX web development framework, presumably so that you can do the same.
2005/6/16
JS/UIX; a complete virtual UNIX machine that runs entirely in JavaScript using DHTML. Well, not entirely complete; the realistic-looking executable files in /bin, upon closer inspection, have sizes of 'n/a', and are basically façades for JavaScript pixie dust that does what they are meant to; also, the shell doesn't actually support any scripting commands. However, you can create and access files, and it even has a mostly usable implementation of vi.
2005/5/17
The LiveJournal people have unveiled their distributed identity system. Temporarily dubbed "yadis", it's based on FOAF and an AJAX-esque backchannel (though does not need to use AJAX technologies, or even JavaScript), and will ultimately allow sites to accept users authenticated on other sites; it also stands a good chance of somehow finding its way into the next version of SixApart's TypeKey. Update: It has now been renamed "OpenID", and also has a nifty, and somewhat Apple-esque, grey-and-orange icon.
2005/4/26
Could Microsoft's new search engine be giving higher rankings to sites hosted on Microsoft IIS?
2005/4/4
Another reason to not install Flash in your web browser (or, at least, switch it off and start it manually when you need it); not only is Flash used primarily for making ads more annoying, but now it can bypass cookie privacy controls to keep track of your web-browsing habits. (via /.)
Macromedia have a page where you can access your Flash plug-in's privacy settings; if you're using Firefox, you may also want to install Flashblock, which disables Flash by default but lets you load Flash applets on a case-by-case basis.
2005/3/28
Apparently, it is possible (just) to use the PlayStation Portable as a web browser. Either the PSP's firmware/OS or the game WipeOut Pure contains a fully-featured web browser, with JavaScript and all. Mind you, the only way to use it seems to set up a local network that intercepts DNS calls to Sony's web servers.
2005/3/3
The latest in solutions to problems you may not have been aware of: Gravatar, a site that lets people have user icons globally visible on all blogs which support them. The problem is, the unique identifier used to select your icon is the user's email address, which presumes means that, to use this system, the user has to trust all blogs they use it on not to expose their email address to spammers.
Ten years ago, having a single, unique, permanent and publicly-available email address was seen as a good idea; it gave one an online identity, a convenient means of contactability. That was a more innocent time; a time when the internet had, until recently, been a quiet, friendly academic/research community network, home to nothing more hostile than Emacs-vs.-vi flamewars, and some people still chose not to put passwords on their accounts. Then came the carpetbaggers and chickenboners and script kiddies with their spam-sending scripts and email harvesters, and it all changed.
The reasoning behind Gravatar appears to be stuck in the pre-spam golden age of the internet, where an email address is something you publicise rather than hide, and the idea of letting untrusted strangers (or their web sites) have your email address doesn't set off alarm bells. Which is why it's probably doomed to failure.
2005/2/21
This looks cool; it's a web/DHTML-based bitmap font editor, like those ones they had in the 8-bit days. Once you've finished your font, press the button and it sends you a TrueType file of it.
2005/2/9
A fairly informative dissection and analysis of Google Maps and how it does its magic. It's pretty interesting; unlike GMail (the other example of an impressive DHTML-based interface from Google), Maps doesn't use XMLRPC, but instead just fetches tiles in JavaScript and uses a hidden frame to communicate with the server, and the browser's inbuilt XSLT engine to parse the result. Which all makes for some very impressive hack value.
2005/2/8
Google once again raises the bar of what you can do with a web browser. Their latest is Google Maps, an entirely DHTML-based, instantly responsive, scrollable, zoomable map. Functionally, it doesn't seem to do anything that online street maps haven't done for a few years now, but that's not the point; it's the way it does it. Where street maps until now have been clunky and slow, Google Maps feels instantaneous; you can drag the map around, zoom it in and out, and new tiles load on demand. (On a fast connection, it's not slow enough to be annoying.) And the way it displays signposts, with composited Gaussian-blurred shadows, looks pretty cool too. Currently, they only have North America, and only have detailed maps for the United States, but then again, it's still in beta, so hopefully they'll add other parts of the world soon.
2005/2/7
A h4x0r group named Shmoo has revealed a new web-spoofing attack which takes advantage of Unicode characters which look like ASCII characters but aren't, allowing spoofers to register sites like http://www.pаypal.com/ (note that the first 'a' isn't an 'a', but rather Unicode character #1072, the Cyrillic small 'a'). A demo page with two dodgy links is here.
Such attacks, of course, only work if Unicode domain names are allowed. This is one of the few times that Internet Explorer users are safer than Mozilla/Firefox users, as IE doesn't support international domain names out of the box. If you're using Firefox, you may be able to fix it by following the following procedure (via bOING bOING):
1) Goto your Firefox address bar. Enter about:config and press enter. Firefox will load the (large!) config page.
2) Scroll down to the line beginning network.enableIDN -- this is International Domain Name support, and it is causing the problem here. We want to turn this off -- for now. Ideally we want to support international domain names, but not with this problem.
3) Double-click the network.enableIDN label, and Firefox will show a dialog set to 'true'. Change it to 'false' (no quotes!), click Ok. You are done.
4) Go check out the shmoo demo again and notice it no longer works.
Of course, if you practice safe web access, you won't be entering your bank details or whatever after following a link (however kosher-looking) from an untrusted source in the first place, but only after having typed it in with your own hands or selected it from your local bookmarks.
2005/1/19
Google have developed a solution for stopping comment spam, or, more precisely, for denying spammers any search engine-related benefits from getting their URLs all over blogs, guestbooks and bulletin boards. From now on, any links on a web page with the rel="nofollow" attribute will be ignored by search engines. This has broad support; on the search engine side, Google, Yahoo! and MSN Search are heeding this tag, and various blogging tool providers, including SixApart, LiveJournal, Blogger and WordPress, have added automatic support of this link to their comment/trackback mechanisms. (As, of today, has this blog.)
Which seems like a pretty elegant solution; rather than shutting down comments or removing functionality (such as the ability of commenters to include links to their sites or relevant pages or otherwise leverage the hypertextual nature of the web), marking the links as not endorsed by the site, and to be ignored by participating search engines (which should soon be all of them, given that it's an excellent indicator of potential link relevance, and not heeding it can impair the relevance of the engine's results).
2005/1/12
bOING bOING has uncovered, entirely by accident, an online guestbook, apparently in the demo section of a guestbook software site, which ended up being used as an appointment diary by a Florida brothel/escort agency.
We have two new girls: Mercedes and Rose. Please put a wheelchair next to Rose (meaning don't book her) until we get proof of age from her. Of course, if anyone needs "Clarity" forms, they can get them at the pickup spOther than the wacky hijinks that go on in the course of running such an establishment, it contains details such as workers' real names and clients' phone numbers; either "Anne-Marie" (the operator of the brothel; real name: "Frank") was oblivious to the privacy implications of using a free online guestbook test page for storing confidential information, or he just didn't care.
On a tangent, The Age has the poignant story of one man's career as a (gay) phone-sex worker:
One call that really tugged at my heartstrings was someone who called from the country. He had just lost his boyfriend in a car crash and said he was feeling very lonely. The worst part of it was that, because he was from a small town where "you'd get the crap beaten out of you if they found out you were gay", he had no one he could talk to. So he called me. I didn't know what to say. What's a sex phone operator supposed to say in these circumstances? My 20-minute coffee with the boss certainly didn't include a crash course in grief counselling. All I could suggest was that he get out of town every now and again.
2005/1/6
It's confirmed: SixApart (the company set up by Bay Area A-list blogerati who brought you Movable Type and TypePad) have bought LiveJournal (an Oregon-based social-network/journal system most commonly associated with goths and 12-year-old girls). SixApart's FAQ is here, LiveJournal's announcement is here. It appears to be a friendly deal, and SixApart indicated that they will run the services separately, rather than, say, rolling one into the other and using the remaining brand-name for niche marketing or something, and also said that they won't plaster LJ with ads or anything.
Meanwhile, SixApart president (and former black-clad teenager) Mena Trott has more to say here:
I believe that LiveJournal has, unfortunately, received a bum rap because many have considered the postings on LiveJournal to be trivial. It's sort of like a vicious circle: Journalists make fun of webloggers saying that they only post about their cats, webloggers make fun of LiveJournalers saying that they only post about high school angst and LiveJournalers make fun of webloggers saying that they are SUV-driving yuppies who think they have something important to say (and I'm generalizing). The fact is, webloggers and LiveJournalers are in essence doing the same thing: they are posting their thoughts to people who are important to them. For some webloggers, it's 100,000 people, for others it is 10. For LiveJournalers, it may be 30 people, it may be 3 (or a combination of some number).
The funny thing is, you can have a weblog and a LiveJournal. The fact that some of the funniest and smartest people I know have both only reaffirms that we shouldn't limit ourselves to one sort of publishing/communication mode.
(She hits the nail on the head there. I, for one, have had both for a bit over a year. The way I divide them is that this blog is for communicating with anybody who shares the things I'm interested in and post about, whereas my LiveJournal is for communicating with friends/people I know personally. Consequently, my LiveJournal posts tend to be less interesting (at least to people who don't know me personally), and many of them are friends-only (the use of the social-network data on LiveJournal for authentication goes some way towards restoring the private register, which is otherwise hard to do online conveniently). I generally friend people I know online or in real life, though I still think that LiveJournal should split the "friend" relation into two independent "journals I read" and "people I trust" relations.)
2005/1/5
Rumour has it that Six Apart, creators of Movable Type and TypePad, are about to acquire LiveJournal, for an undisclosed sum. I wonder whether this will mean them folding the two services together completely, merging the codebases whilst keeping LiveJournal as a "TypePad for teens" brand, keeping them entirely separate as now, or integrating LiveJournal's social networks with TypeKey. And whether this will put a halt on LJ's existing development plans, such as splitting the "friend of" relation into separate reading and trust relations.
2004/9/20
Annoying web interface of the day: Loot.
This is a UK-based classified advertising site, offering listings of real estate, items for sale, personals and so on. Which is all very well, except that some genius had the brilliant idea of not using ordinary web links for ads, but instead doing it all in Javascript. When you click on an ad, it executes a piece of javascript which changes the current window's location for you. This means that it is impossible to open an ad in a separate window or tab; you can only view Loot in one window at a time, linearly going from ad to ad and backtracking as need be.
I have no idea why anybody could have thought that sort of user-hostile web design is a good idea. It's not to encourage people to pay (paid users get the same interface), it doesn't give the site a slick, Gmail-like interface (it's just a normal web site, except that you can't easily view more than one thing at a time), or otherwise contribute to the user experience (unless, perhaps, the user is a submissive masochist), it doesn't even seem to aim for the holy grail of Protecting Valuable Intellectual Property. The only possibilities I can think of are: (a) that they were betting that, by slowing down user browsing of their site, they could eke more time-limited ad-viewing tokens out of their users, and that no competing website would steal their customers by offering a less annoying experience, or (b) that whoever designed it just wanted to show off their web kung fu ("Look mum, Javascript!")
2004/6/7
Another use of technology to make democracy more of a reality (as opposed to just voting for who'll take orders from the people that matter for the next 3 to 4 years): TheyWorkForYou.com, from the team that created FaxYourMP.com, takes the text of Hansard, the transcript of debates in Britain's House of Commons, and converts it into a threaded, linkable discussion form, not unlike, say, LiveJournal or something. Not only that, but it keeps tabs on MPs, including biographies, lists of their interests (shares, board memberships and such, as well as details of overseas trips and gifts received), how often they speak, performance in replying to faxes, and how often they rebel against their own party line. Here's Tony Blair, for example, and the ultra-groovy member for West Bromwich East.
This sort of system promises to reinvigorate democracy and hold politicians to be more accountable to their constituents. (Do you know what your MP has been doing?) I hope that the TheyWorkForYou team plan on releasing the code, because this sort of thing should be exported to other parliamentary democracies. I'd like to see one in Canberra, keeping tabs on Federal Parliament, for one, and ones for state Parliaments; not to mention US Congress, the EU Parliament, and so on. (via bOING bOING)
2004/4/6
They're embedding web servers in a lot of things these days; like, for example, frogs. (via 1.0)
2004/2/14
I'm Wayne Kerr, and if there's one thing I hate... it's web sites which sacrifice usability to be "arty". Such as the ACMI site. I went to book a ticket to one of the Cremaster screenings, but there's no indication of where the box office is; the only links are lower-case verbs like "experience", "learn", "play" and so on. Ooh, tres artistique! Now about that ticket I wanted to buy...
2004/1/4
Beware: leading social network websites like LiveJournal, tribe.net and LinkedIn, are dangerously insecure; said sites don't bother with using SSL, sending cleartext passwords across where they may be intercepted:
Paul Martino, CTO of Tribe, chuckled at the idea that his site might use SSL for member logins. "We don't need high industrial strength encryption for that," he said. "We use standard security techniques like unique session IDs."
Some attacks rely on technological vulnerabilities, and others rely on human gullibility and badly-designed user interfaces (i.e., the old spoofed-email-pointing-to-fake-login-page trick). And there's more at risk than adolescent social dramas.
A top-ranked member of a network like eBay might be able to sell more items than her peers. A high-karma user on a site devoted to legal issues could have a tremendous influence over public policy. According to social networks analyst Clay Shirky, identity spoofing is possibly the greatest threat to social discovery networks. "When your reputation is valuable, it becomes worth exploiting. It makes a stolen identity a more valuable commodity."
By impersonating a highly-reputable person, an attacker might gain access to that person's social network, business contacts and private life. Spammers might launch highly personalized campaigns. And sexual predators could use their victims' friend lists to find more people to harass.
Update: Apparently LiveJournal now no longer uses cleartext passwords for login, instead using a challenge/response scheme using JavaScript, with SSL logins for the non-JavaScript-enabled. (I wonder how much a risk login cookies sent in the clear are, though.)
2003/8/16
Lemmings in DHTML/Javascript; a faithful reconstruction of the classic Amiga game, with no Flash/Java involved. Still a work in progress, but impressive as fuck. See it before it's Slashdotted. (via MeFi)
2003/7/23
Ever wonder why Google have a copyright notice at the bottom of their (not exactly intellectual-property-rich) search page? It's not so much to appease the lawyers as it is to let you know where the page ends:
In its early days, the company asked some focus group participants to search for information using its site. But many people, when they went to Google, did nothing for a minute or two. When asked why, these apparent procrastinators said they were waiting for the rest of the site to load. So, the company thought that by putting a copyright notice on its page--something usually found only at the bottom of a fully loaded page--perhaps people would get the hint that the spartan page was fully loaded.
(via TechDirt)
2003/7/1
Mozilla 1.4 is out. And they've finally fixed it so you can disappear the Print/Search buttons that clutter the interface. Though now it freezes when you change virtual desktops, or at random intervals. Time to get familiar with Konqueror, I think.
2003/5/13
CSS Zen Garden; a demonstration of what can be achieved visually just by tweaking CSS stylesheets. Hmmm... (via bOING bOING)
2003/2/20
Oh yes, yesterday's blog meetup was good. It was at the Gin Palace again, which is always good (though not cheap). A lot of people turned up, and a lot of good (if punctuated) conversation occurred.
I was looking at the blog meetup page and found that there's now an Iraq Crisis meetup. It seems to be mostly anti-war types, at least in Australia. I'm surprised there's no Fisking Meetup.
I looked at some other ones too, and found that there's also an indie meetup (which should be fun, as long as it's not overrun by mooks who think that Interscope is an indie label), a Smiths meetup (which sounds like a great place to get dates, or just an all-round fun place to be) and even a shoegazer meetup, for all the shoegazer/ethereal/4AD/swirlygoth fans. Who'd have thought there'd be enough people in Melbourne for one of those?
(Btw, what's the difference between the Goth Meetup and the Teen Vampire meetup?)
2003/2/17
Google buys Pyra Labs, the company who brought blogging to the masses with Blogger (that's the web-based blogging tool everybody used before Movable Type) and free ad-supported hosting service BlogSpot (that's sort of the GeoCities of blogs).
2002/9/14
Web Designer Builds Home out of Flash; hits the nail right on the head.
Conventional home builders aren't concerned just yet that they will become obsolete. "I see a fundamental usability issue with Flash homes," relates Greg Watson of J & G Builders. "For example, from home to home there will be design differences. In one house if you turn the door knob it'll open the door, but in another the house might start dancing."
(via Gimbo)
2002/8/14
I'm Wayne Kerr, and if there's one thing I hate... it's web sites which disable your browser's right mouse button, just to show that it can be done/to assert control over your web browsing. Like this one. If I want to open a link in a Mozilla tab, instead of the menu I get a pop-up message saying "function disabled". Oooh, I stand in awe of your godlike JavaScript skills. Wanker.
2002/7/7
Could this be the best 404 ever?
Welcome to Zork. This version created 11-MAR-91 (PHP mod 25-OCT-2001) There are 4 users playing Zork. You are in an open field west of a big white house with a boarded front door. There is a small mailbox here. >
(via Peter, who really should update his blog more often)
2002/3/3
Social engineering: A sneaky way to find out a friend's secrets with the use of a fake web survey. Though in this case, "secrets" is limited to sexual history and fantasies, so this is probably more of interest to excitable adolescents or fans of teen gross-out comedies. (via bOING bOING)
2001/11/7
An inventory of CGI-script attack techniques commonly used by crackers and worms. If you write CGI scripts, go read. (via Slashdot)
2001/10/31
Sick of pop-up ads and other nastiness? Well, if you use Mozilla, here's how to switch off JavaScript "features" on a site-by-site basis. This is not in the UI yet, either because they haven't gotten around to doing it, or because they've snuck it in under AOL's nose.
2001/1/4
No marks for The Designers Republic on their web design, mostly because they don't actually use HTML and just make everything embedded Flash. Having to start VMWare to access their web site (you try finding a working Flash plug-in for Linux) is annoying.
(And the Macromedia Flash plug-in for Linux is unusable. It works, but it grabs the audio device, and freezes Netscape until it gets it. Having to stop listening to your MP3s because there's a Flash ad on a page is just not acceptable, even for the leprous beggars who don't use Windows.)
Anyway, if you want to snarf it from a UNIX machine, the Designers Republic's free screen saver may be found here (for the Mac) or here (for Windows). (Cute URLs, guys...)
I'm Wayne Kerr, and if there's one thing I hate... it's that stupid JavaScript scroller gimmick. You know, the one that some pages have, scrolling a flickery message (typically something droolingly inane like "Hi! Welcome to my web page!") through your browser's status bar. You can't stop it (as you can GIF animations), you can't see any links you put the cursor over, and it's irritating as hell. And no, it's not cool, or clever, and it makes the designer of the web page (or the pointy-haired management type who signed off on it) look like a cretin. Unfortunately, the Ausway street directory home page has succumbed to this particular lapse of taste.
2000/12/19
Statistic of the day: MS Internet Exploiter is the most popular browser on Slashdot? (At time of writing it was leading with 39%, with Nyetscape having 35%.)
2000/12/8
Mozilla 0.6 is out; it's basically bug-for-bug identical to Netscape 6.0, except less bloated, not quite as sluggish and without the advertisements in the menus. (via Slashdot)
2000/12/6
Browsing the Macromedia Flash website, I discovered this "feature" entitled "What You Print Is Not What You See." This basically means when you print a web page, that little Flash banner ad can print out multiple pages worth of advertising drivel (if the designer wants it to). This is akin to having a unseen, secret speaker on your car radio that mysteriously blabs ads when advertisers want. Hey, thanks for thinking of the users, Macromedia!
2000/9/30
This looks most interesting: Python WebWare; not as heavy as Zope, but it has some interesting-looking components such as Python Server Pages and WebKit.
2000/9/29
I'm Wayne Kerr, and if there's one thing I hate... it's web sites which require JavaScript to work, for no reason other than custom pop-up windows looking cool. Sadly to say, the Fringe Festival site is one example.
2000/4/23
2000/1/10
Slightly tongue-in-cheek Salon article proves that Borges wrote about the Web:
What are the "infinite stories, infinitely branching" of his character Herbert Quain's book "April March," if not hypertext? What is the purpose of Ireneo Funes, the paralyzed young man unable to forget any aspect of anything he has ever seen, if he is not to represent search engines burdened with memories of long-inactive links? What is Tlön, the virtual world in "Tlön, Uqbar, Orbis Tertius" that gradually overtakes the real one, if not the cyberspace for which the physical world is rapidly becoming a quaintly antiquated sketch?